Bayes Coffee Talk | University of Edinburgh
Do Deep Ensembles Capture Uncertainty
in Graph Neural Networks?
Viacheslav (Slava) Borovitskiy
https://vab.im

Talk Outline
Introduction
- Motivating uncertainty quantification
- Main approaches for uncertainty quantification
- Graph Machine Learning
- Origins of the research question
Do Deep Ensembles Capture Uncertainty in Graph Neural Networks?
- Benchmarking
- Analysis
- Hypothesis
Summary and Future Work
Motivating uncertainty quantification
Motivating uncertainty quantification
:
Model-based decision-making
Model-based decision-making
Probabilistic models: input ⟶ distribution (prediction + uncertainty)
Allows computing queries like probability of improvement: $\!\alpha(x) \!=\! \mathbb{P} \! \del{f(x) \!>\!\! f^*}$
They can drive selection of the next point to evaluate [Bayesian optimization]
Main approaches for uncertainty quantification
Main approaches for uncertainty quantification
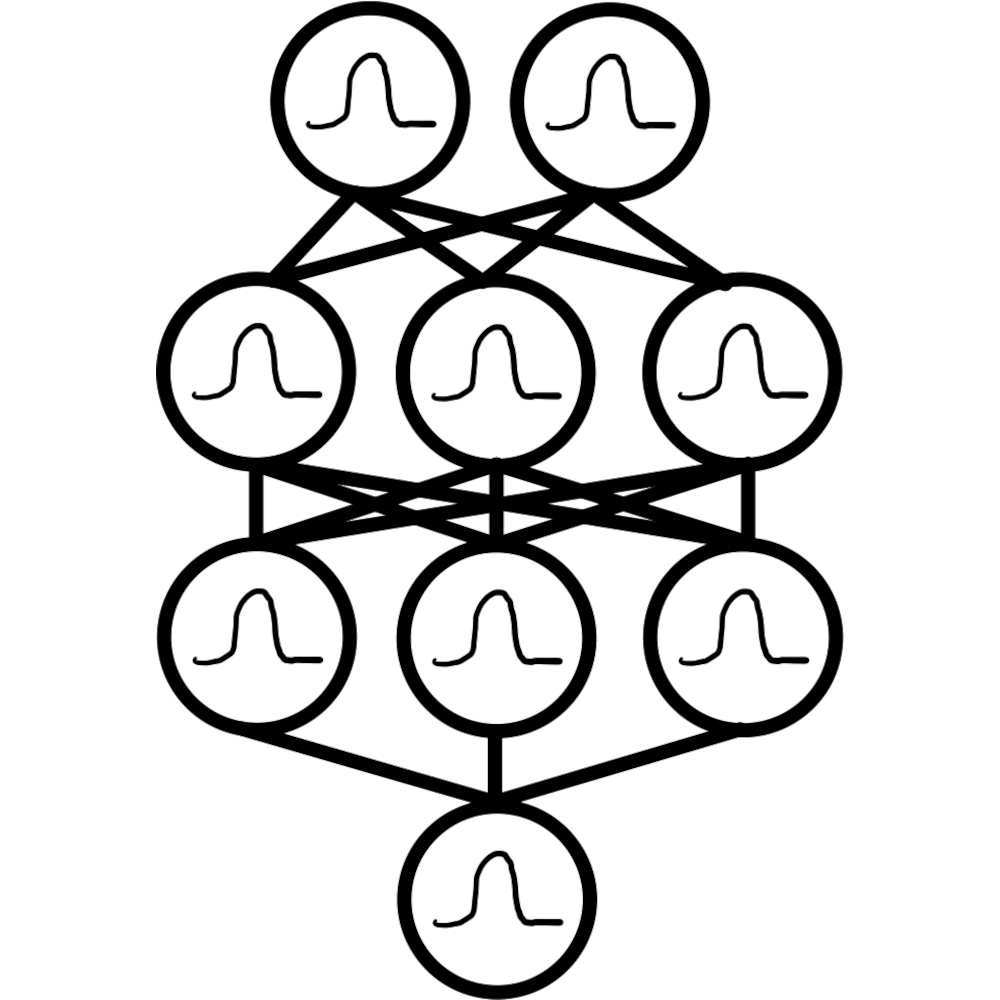
Bayesian neural networks
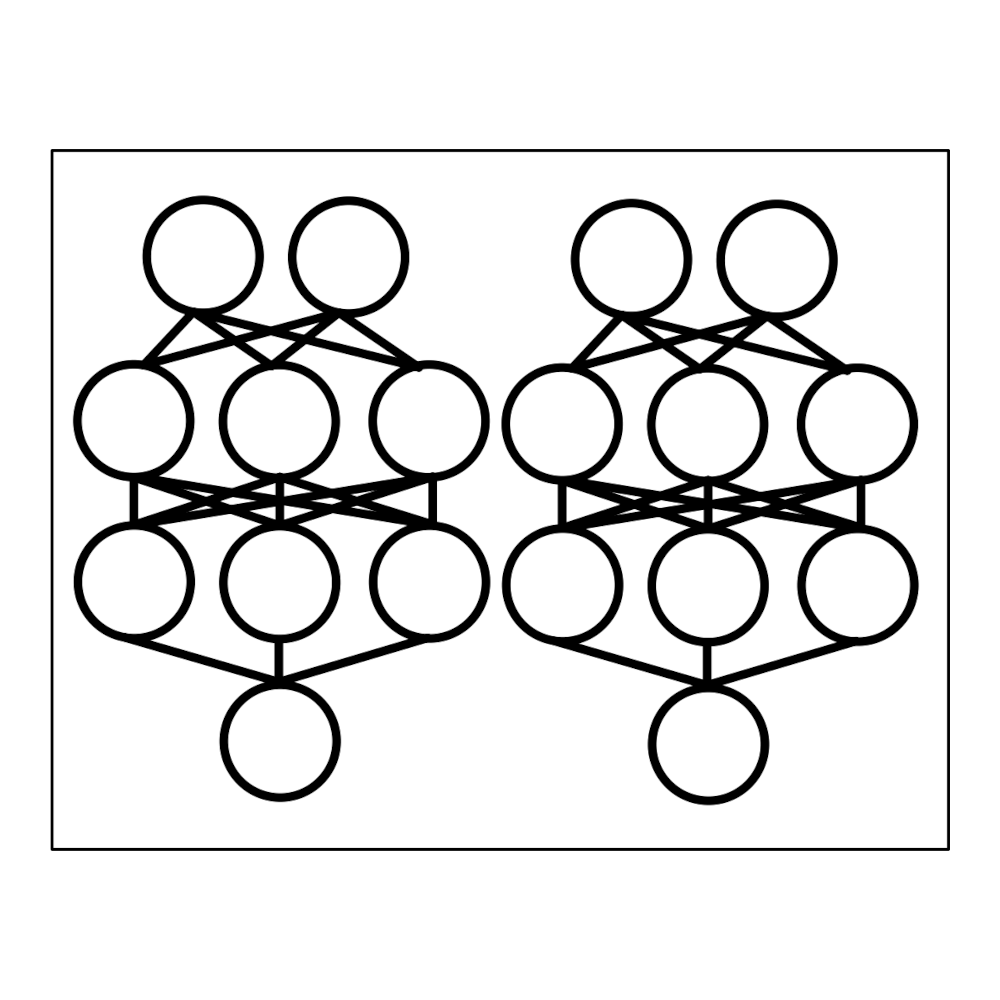
Deep ensembles
$\underbrace{\hphantom{\text{Bayesian Neural Networks}\qquad{Deep ensembles}}}_{\text{defined by neural network architectures}}$
Gaussian processes
$\underbrace{\hphantom{\text{Gaussian Processes}}}_{\text{defined by kernels}}$
Graph Machine Learning
Includes many different settings.
Node-level tasks


Graph-level tasks
Also: edge-level tasks, graph generation, etc.
Example setting: Node regression
Example setting: Node regression
$$ f : V \to \R $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g1.svg}}\Big) = 2 $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g2.svg}}\Big) = 3 $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g3.svg}}\Big) = 5 $$
Example setting: Probabilistic node regression
$$ f : V \to \text{distributions over } \R $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g1.svg}}\Big) = \f{N}(2, 0.5^2) $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g2.svg}}\Big) = \f{N}(3, 0.2^2) $$
$$ f\Big(\smash{\includegraphics[height=2.75em,width=1.5em]{figures/g3.svg}}\Big) = \f{N}(5, 0.7^2) $$
Origins of the research question
Benchmark: Caltrans Performance Measurement System (PeMS)
San Jose highway network: graph with 1016 nodes
325 labeled nodes with known traffic speed in miles per hour
Use 250 labeled nodes for training data and 75 for test data
Dataset details: Borovitskiy et al. (AISTATS 2021)
Trivial baseline
Trivial baseline
: prediction
: uncertainty
Results
Results
Figure: Uncertainty estimates of a geometric Gaussian process.
PEMS benchmark: GNN ensemble fails miserably w.r.t. NLL.
Do Deep Ensembles Capture Uncertainty in Graph Neural Networks?
Do Deep Ensembles Capture Uncertainty in Graph Neural Networks?
Is the failure on PEMS an isolated anomaly?
Or is it symptomatic of a broader incompatibility
between deep ensembles and graph neural networks?
We investigated this for message passing graph neural networks.
(GCN, GAT, etc.)
A Comprehensive Benchmark
Evaluating across diverse tasks, scales, and structural properties.
Node Classification
- Cora & Citeseer
(Classic, Small) - Tolokers2
(Modern, larger)
Node Regression
- Artnetviews
(Modern, larger) - Chameleon
(Benign heterophily)
Graph Regression
- QM9-5% HOMO-LUMO
(Classic, data-scarce)
Evaluating Predictive Uncertainty
Our primary metric is the Negative Log-Likelihood (NLL).
Conceptually:
$$ \text{NLL} \approx \text{Prediction Error} + \text{Uncertainty Calibration} $$
To achieve a good NLL, a model must be accurate
AND "know what it doesn't know".
Deep Ensembles: Graphs vs. Computer Vision
How much more likelihood does the ensemble assign to test data?


Computer Vision
Typical improvements: ~20%
Graph Neural Networks
Improvements: often as low as 0.1%
The gains exist, but they are surprisingly marginal. Why?
Disentangling NLL Gains
Do deep ensembles improve uncertainty, or just point predictions?

NLL
- DE-R Baseline: ensemble's mean prediction + variance of a single model.
- Observation: DE-R — nearly identical NLL improvements to DE.
Conclusion: Ensembling on graphs acts primarily as a variance-reducing smoother for point predictions, not a better uncertainty estimator.
How do Deep Ensembles capture uncertainty?
Total predictive uncertainty breaks down into:
Aleatoric Uncertainty
Irreducible uncertainty
(e.g., measurement errors)
DE: Averaging individual model uncertainties
Epistemic Uncertainty
The model's lack of knowledge
(e.g., in regions with no training data)
DE: Captured by disagreement among models
If individual models in an ensemble do not disagree,
they cannot capture epistemic uncertainty.
The Root Cause: Epistemic Collapse
Let's decompose the uncertainty of our GNN ensembles.


GNNs consistently converge to highly similar predictions.
Epistemic uncertainty collapses to near-zero.
Because they do not meaningfully disagree, they neutralize the very mechanism that makes deep ensembles work (for uncertainty quantification).
Why do GNNs Collapse? (Hypothesis)
Deep ensembles rely on a highly non-convex loss to find diverse solutions.
Weight space: Non-convex
Averaging weights degrades performance dramatically. Thus individual models live in different regions of the weight space.
Function space: Convex-like
Despite having completely different weights, individual models all implement virtually the same predictive function.
Hypothesis: The structural inductive bias of message passing acts as a homogenizing force, severely restricting functional diversity.
Summary & Future Work
Summary & Future Work
Key Takeaways
- Message passing GNN ensembles only offer marginal NLL gains (in contrast to deep ensembles in computer vision).
- Improvements come from smoothing predictions, not qualitatively better uncertainty estimates.
- Epistemic collapse: Functional convexity destroys the core mechanism through which ensembles improve uncertainty.
Future Directions
- How does message passing induce "convexity"?
- What about graph transformers?

P. C. Vieira, P. Ribeiro, V. Borovitskiy
(Available on arXiv)