Uncertainty in multivariate, non-Euclidean,
and functional spaces: theory and practice
Gaussian Vector Fields on Manifolds and Graphs
Viacheslav (Slava) Borovitskiy

Uncertainty-enabled models: input ⟶ prediction + uncertainty.
Gaussian processes (GPs) — gold standard.
— random functions with jointly Gaussian marginals.
Bayesian learning: prior GP + data = posterior GP
Prior GPs are determined by kernels (covariance functions)
— have to be positive semi-definite (PSD),
— not all kernels define "good" GPs.
This talk: defining priors / kernels.
$$
\htmlData{class=fragment fade-out,fragment-index=6}{
\footnotesize
\mathclap{
k_{\nu, \kappa, \sigma^2}(x,x') = \sigma^2 \frac{2^{1-\nu}}{\Gamma(\nu)} \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}^\nu K_\nu \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}
}
}
\htmlData{class=fragment d-print-none,fragment-index=6}{
\footnotesize
\mathclap{
k_{\infty, \kappa, \sigma^2}(x,x') = \sigma^2 \exp\del{-\frac{\norm{x-x'}^2}{2\kappa^2}}
}
}
$$
$\sigma^2$: variance
$\kappa$: length scale
$\nu$: smoothness
$\nu\to\infty$: RBF kernel (Gaussian, Heat, Diffusion)

$\nu = 1/2$

$\nu = 3/2$

$\nu = 5/2$

$\nu = \infty$


$$ k_{\infty, \kappa, \sigma^2}(x,x') = \sigma^2\exp\del{-\frac{|x - x'|^2}{2\kappa^2}} $$
$$ k_{\infty, \kappa, \sigma^2}^{(d)}(x,x') = \sigma^2\exp\del{-\frac{d(x,x')^2}{2\kappa^2}} $$
Manifolds: not PSD for some $\kappa$ (in some cases—for all) unless the manifold is isometric to $\mathbb{R}^d$.
Feragen et al. (CVPR 2015) and Da Costa et al. (Preprint 2023).
Graph nodes: not PSD for some $\kappa$ unless can be isometrically embedded into a Hilbert space.
Schoenberg (Trans. Am. Math. Soc. 1938).


On $\mathbb{R}^d$, we have $$ k_{\infty, \kappa, \sigma^2}(x, x') \propto \mathcal{P}(\kappa^2/2, x, x'), $$ where $\mathcal{P}$ is the heat kernel, i.e. the solution of $$ \frac{\partial \mathcal{P}}{\partial t}(t, x, x') = \Delta_x \mathcal{P}(t, x, x') \qquad \mathcal{P}(0, x, x') = \delta_x(x') $$ Alternative generalization: use the above as the definition of the RBF kernel.
☺ Always positive semi-definite + Simple and general inductive bias.
☹ Implicit, requires solving the equation.
Matérn kernels $k_{\nu, \kappa, \sigma^2}$ can be defined whenever $\mathcal{P}(t, x, x')$ is defined:
$$ k_{\nu, \kappa, \sigma^2}(x, x') \propto \sigma^2 \int_{0}^{\infty} t^{\nu-1+d/2}e^{-\frac{2 \nu}{\kappa^2} t} \mathcal{P}(t, x, x') \mathrm{d} t $$(there are other—usually equivalent—definitions)
☺ Always positive semi-definite + Simple and general inductive bias.
☹ Implicit.
For example, on a compact Riemannian manifold of dimension $d$: $$ k_{\nu, \kappa, \sigma^2}(x,x') = \frac{\sigma^2}{C_{\nu, \kappa}} \sum_{n=0}^\infty \Phi_{\nu, \kappa}(\lambda_n) f_n(x) f_n(x') $$
Also:
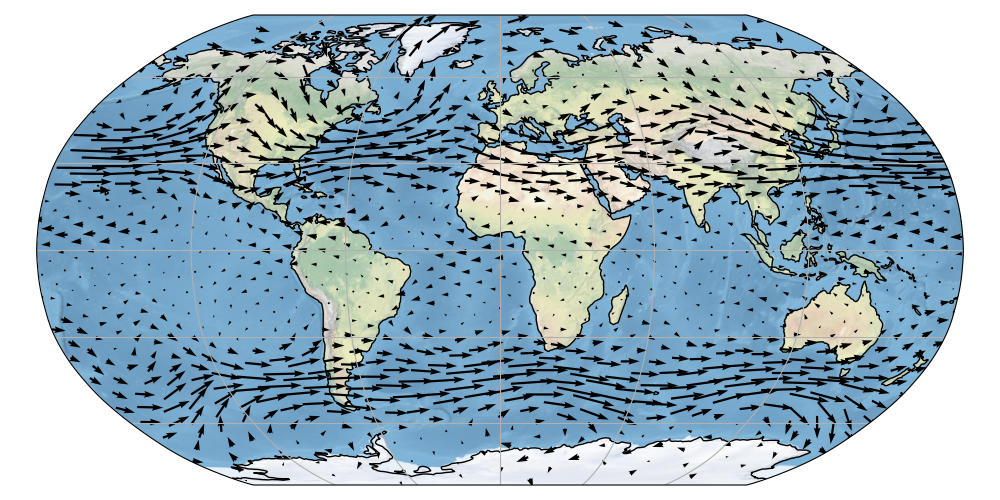
Euclidean case: vector field = vector-valued function.
On manifolds: vector-valued functions with outputs tangent to the manifold.


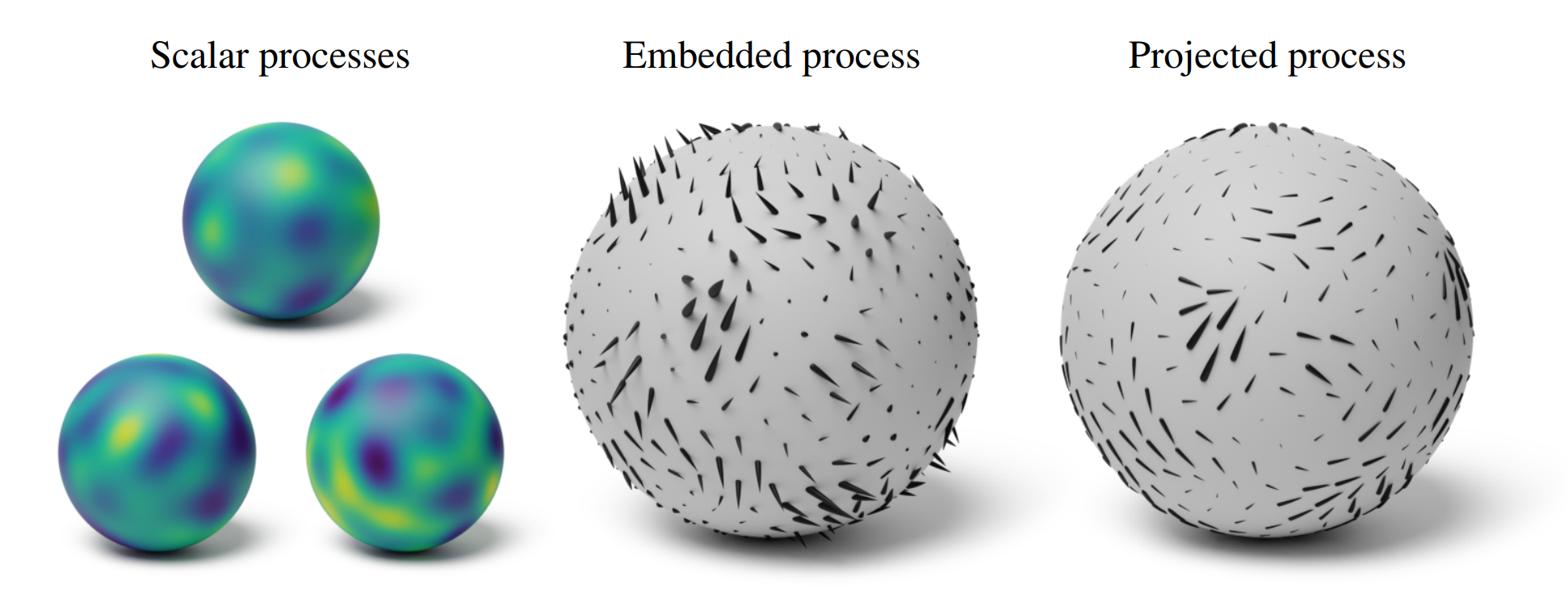
Projected Gaussian Processes—simple and general Gaussian vector fields (GVFs).
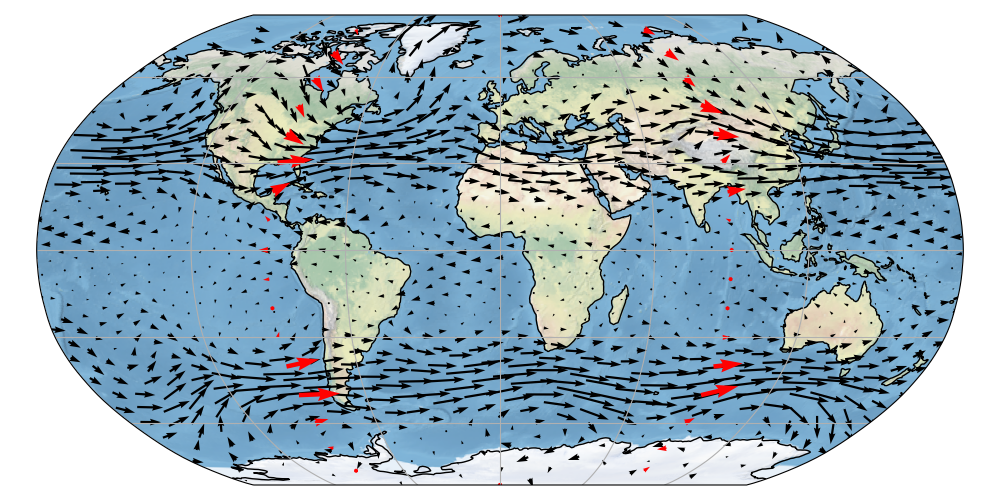
Experimental Results: projected GPs perform quite well.



Hodge theory: heat equation on vector fields.
Define $ k_{\infty, \kappa, \sigma^2}(x, x') \propto \mathcal{P}(\kappa^2/2, x, x'), $ where $$ \frac{\partial \mathcal{P}}{\partial t}(t, x, x') = \Delta_x \mathcal{P}(t, x, x') \qquad \mathcal{P}(0, x, x') = \delta_x(x') $$ and $\Delta$ is the Hodge Laplacian.
Define Matérn GVFs in terms of $\mathcal{P}$ in the usual way.
Specifically, on a compact oriented Riemannian manifold $M$ of dimension $d$: $$ k_{\nu, \kappa, \sigma^2}(x,x') = \frac{\sigma^2}{C_{\nu, \kappa}} \sum_{n=0}^\infty \Phi_{\nu, \kappa}(\lambda_n) s_n(x) \otimes s_n(x') $$
Context: On $\mathbb{S}_2$, $\nabla f_n$ and $\star \nabla f_n$ form the basis of orthogonal eigenfields ($\star$—$90^{\circ}$ rotation).
Motivation: deep Gaussian processes (later).

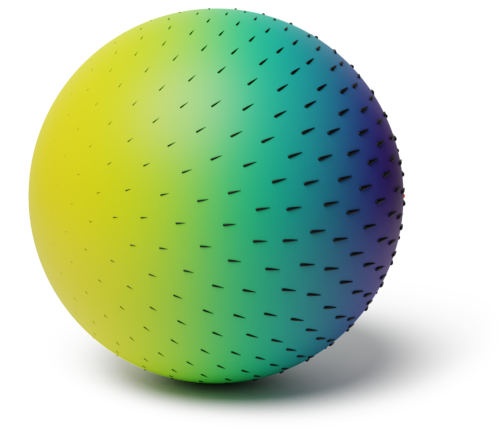
In $2$-D, each $s_n$ is either divergence-free, curl-free, or both (harmonic).


Only use one type: kernels $k_{\nu, \kappa, \sigma^2}^{\text{div-free}}$, $k_{\nu, \kappa, \sigma^2}^{\text{curl-free}}$, $k_{\nu, \kappa, \sigma^2}^{\text{harm}}$.
Hodge-compositional kernel: fit $\alpha, \beta, \gamma$ and $\kappa_1, \kappa_2, \kappa_3$ in
$$ k_{\nu,\kappa_1, \alpha}^{\text{div-free}} + k_{\nu, \kappa_2, \beta}^{\text{curl-free}} + k_{\nu, \kappa_3, \gamma}^{\text{harm}} $$
| Kernel | MSE | NLL |
|---|---|---|
| Pure noise | 2.07 | 2.89 |
| Projected Matérn | 1.39 | 2.33 |
| Hodge–Matérn | 1.67 | 2.58 |
| div-free Hodge–Matérn | 1.10 | 2.16 |
| Hodge-compositional Matérn | 1.09 | 2.16 |
Hodge-compositional Matérn does best and is the easiest to use.



Context: Jaquier et al. (2022) used manifold Matérn GPs for optimizing robotics control policies.
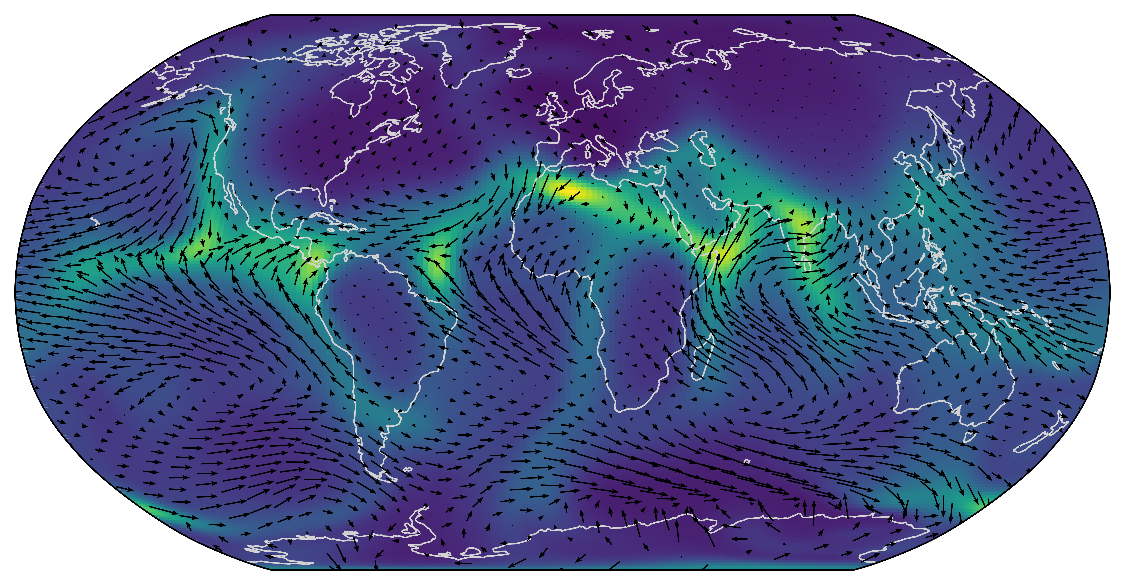
Performs much better than a shallow GVF for denser data.
Context: Dutordoir et al. (2020) suggested mapping Euclidean data to the hypersphere and using GPs on $\mathbb{S}_d$. There, manifold Fourier feature enable faster variational inference (VI).
State-of-the-art: Wyrwal et al. (2025) tried doing the same for deep GPs based on projected GPs.
Maybe use Hodge GVFs (see open problem #1) or different maps $\mathbb{R}^d \to \mathbb{S}_{d'}$?
Let $M$ be a manifold and $G = (V, E)$ a graph.
Simplest way to see the connection: consider the gradient $f = \nabla g$.
Main idea: alternating functions on edges are analogous to vector fields.
We can define divergence of an alternating edge function $f$ as $$ (\operatorname{div} f)(x) = - \sum_{x' \in N(x)} f((x, x')) \qquad x \in V $$ where $N(x)$ is the set of neighbors of $x$.
Take a graph $G = (V, E)$ and add an additional set of triangles $T$:
For each $t \in T$, $t = (e_1, e_2, e_3)$ is a triangle with edges $e_1, e_2, e_3 \in E$.

Can also be extended beyond triangles: cellular complexes.
Curl of an alternating edge function $f$ (mind the orientations/signs)
$$ (\operatorname{curl} f)(t) = \sum_{e \in t} f(e) \qquad t \in T. $$
Can also define Hodge Laplacian matrix $\m{\Delta}$ on simplicial 2-complexes.
It defines the heat kernel $\mathcal{P}$ and through it all Matérn kernels $k_{\nu, \kappa, \sigma^2}$.
Eigenvectors of $\m{\Delta}$ can be split into divergence-free, curl-free, and harmonic:


If $r^{i \to j}$ is the exhange rate between currency $i$ and currency $j$, then
$$r^{i \to j} r^{j \to k} = r^{i \to k}$$
This is curl-free condition for $\log r^{i \to j}$.
Hodge-compositional kernels can infer it from data.

Currently: has graph edges☺, doesn't have Gaussian vector fields ☹.
M. Alain, S. Takao, B. Paige, and M. P. Deisenroth. Gaussian Processes on Cellular Complexes. International Conference on Machine Learning, 2024.
V. Borovitskiy, I. Azangulov, A. Terenin, P. Mostowsky, M. P. Deisenroth, and N. Durrande. Matérn Gaussian Processes on Graphs. Artificial Intelligence and Statistics, 2021.
V. Borovitskiy, A. Terenin, P. Mostowsky, and M. P. Deisenroth. Matérn Gaussian Processes on Riemannian Manifolds. Advances in Neural Information Processing Systems, 2020.
D. Bolin, A. B. Simas, and J. Wallin. Gaussian Whittle-Matérn fields on metric graphs. Bernoulli, 2024.
S. Coveney, C. Corrado, C. H. Roney, D. OHare, S. E. Williams, M. D. O'Neill, S. A. Niederer, R. H. Clayton, J. E. Oakley, and R. D. Wilkinson. Gaussian process manifold interpolation for probabilistic atrial activation maps and uncertain conduction velocity. Philosophical Transactions of the Royal Society A, 2020.
N. Da Costa, C. Mostajeran, J.-P. Ortega, and S. Said. Invariant kernels on Riemannian symmetric spaces: a harmonic-analytic approach. Preprint, 2023.
A. Feragen, F. Lauze, and S. Hauberg. Geodesic exponential kernels: When curvature and linearity conflict. Computer Vision and Pattern Recognition, 2015.
M. Hutchinson, A. Terenin, V. Borovitskiy, S. Takao, Y. W. Teh, M. P. Deisenroth. Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge Independent Projected Kernels. Advances in Neural Information Processing Systems, 2021.
N. Jaquier, V. Borovitskiy, A. Smolensky, A. Terenin, T. Asfour, and L. Rozo. Geometry-aware Bayesian Optimization in Robotics using Riemannian Matérn Kernels. Conference on Robot Learning, 2021.
P. Mostowsky, V. Dutordoir, I. Azangulov, N. Jaquier, M. J. Hutchinson, A. Ravuri, L. Rozo, A. Terenin, V. Borovitskiy. The GeometricKernels Package: Heat and Matérn Kernels for Geometric Learning on Manifolds, Meshes, and Graphs. Preprint, 2024.
R. Peach, M. Vinao-Carl, N. Grossman, and M. David. Implicit Gaussian process representation of vector fields over arbitrary latent manifolds. International Conference on Learning Representations, 2024.
D. Robert-Nicoud, A. Krause, and V. Borovitskiy. Intrinsic Gaussian Vector Fields on Manifolds. Artificial Intelligence and Statistics, 2024.
I. J. Schoenberg. Metric spaces and positive definite functions. Transactions of the American Mathematical Society, 1938.
K. Wyrwal, A. Krause, and V. Borovitskiy. Residual Deep Gaussian Processes on Manifolds. International Conference on Learning Representations, 2025.
M. Yang, V. Borovitskiy, and E. Isufi. Hodge-Compositional Edge Gaussian Processes. Artificial Intelligence and Statistics, 2024.
Vector fields can be thought of as $1$-forms. $\Omega^k(M)$ is the space of $k$-forms.
Thm 1. $\Omega^k(M) = \operatorname{ker} \Delta \oplus \operatorname{im} \mathrm{d} \oplus \operatorname{im} \mathrm{d}^{\star}$, where
Thm 2. $d, d^{\star}$ map eigenforms to eigenforms, preserving orthogonality.
On $\mathbb{S}_2$: $\Omega^0(\mathbb{S}_2) = \Omega^2(\mathbb{S}_2)$ and the eigenforms are spherical harmonics,
On $\mathbb{S}_2$: $d$ is the gradient operator, $d^{\star}$ is gradient plus rotation by $90^{\circ}$.
Consider a vector-valued GP $\v{f}: \R^d \to \R^d$ and $\v{x}, \v{x}' \in \mathbb{R}^d$. Then $$ k(\v{x}, \v{x}') = \mathrm{Cov}(\v{f}(\v{x}), \v{f}(\v{x}')) \in \mathbb{R}^{d \x d} $$
For $x, x' \in M$ (a manifold), and $f$ a Gaussian vector field on $M$.
Hard to generalize the above:
$
f(x) \in T_x M \not= T_{x'} M \ni f(x')
.
$
Instead, for all $(x, v), (x', u) \in T M$, $$ k((x, u), (x', v)) = \mathrm{Cov}(\innerprod{f(x)}{v}_{T_x M}, \innerprod{f(x')}{u}_{T_{x'} M}) \in \mathbb{R} $$
Fix orientation: for each $\{x, x'\} \in E$, choose either $(x, x')$ or $(x', x)$ to be positively oriented. Positively oriented edges can be enumerated by $\{1, .., |E|\}$.
Then, an alternating edge function $f$ can be represented by a vector $\v{f} \in \mathbb{R}^{|E|}$.
If $\m{B}_1$ is the oriented node-to-edge incidence matrix of dimension $|V| \x |E|$,
Take a graph $G = (V, E)$ and add an additional set of triangles $T$:
For each $t \in T$, $t = (e_1, e_2, e_3)$ is a triangle with edges $e_1, e_2, e_3 \in E$.
Can also be extended beyond triangles: cellular complexes.
Let $\m{B}_2$ be an oriented edge-to-triangle incidence $|V| \x |T|$-matrix.
It defines the heat kernel $\mathcal{P}$ and through it all Matérn kernels $k_{\nu, \kappa, \sigma^2}$.
Eigenvectors of $\m{\Delta}$ can be split into divergence-free, curl-free, and harmonic:

Implementation (Colab notebook) — clickable
Doesn't have Gaussian vector fields ☹. To be updated soon.
Currently: graph nodes. Need also: graph edges, metric graph.