NTR Labs Webinar
Sequential Decision Making
with Gaussian Processes
Viacheslav Borovitskiy (Slava)











Gaussian processes — gold standard in uncertainty estimation
Definition. A Gaussian process is random function $f : X \times \Omega \to \R$ such that for any $x_1,..,x_n$, the vector $f(x_1),..,f(x_n)$ is multivariate Gaussian.
The distribution of a Gaussian process is characterized by
Notation: $f \~ \f{GP}(m, k)$.
The kernel $k$ must be positive (semi-)definite.
Takes
giving the posterior Gaussian process $\f{GP}(\hat{m}, \hat{k})$.
The functions $\hat{m}$ and $\hat{k}$ may be explicitly expressed in terms of $m$ and $k$.
Goal: minimize unknown function $\phi$ in as few evaluations as possible.





















Also




Idea. Approximate the posterior process $\f{GP}(\hat{m}, \hat{k})$ with a simpler process belonging to some parametric family $\f{GP}(m_{\theta}, k_{\theta})$.
$O(N^3)$ turns into $O(N K^2)$ where $K$ controls accuracyPriors are usually assumed stationary.
Idea. Approximate with a process of form
$$ \htmlData{class=yoyo}{ \tilde{f}(x) = \sum_{l=1}^L w_l \phi_l(x) \qquad w_l \overset{\textrm{i.i.d.}}{\sim} N(0, 1), } $$
which is easy to sample from.
$O(M^3)$ turns into $O(M L)$ where $L$ controls accuracyIdea. From a parametric family $\f{GP}(m_{\theta}, k_{\theta})$ build another family $\f{GP}(\tilde{m}_{\theta}, \tilde{k}_{\theta})$ which is easy to sample from.
$O(N^3 + M^3)$ turns into $O(N K^2 + M L)$ where $K$ and $L$ control accuracy
$$
\htmlData{class=fragment fade-out,fragment-index=9}{
\footnotesize
\mathclap{
k_{\nu, \kappa, \sigma^2}(x,x') = \sigma^2 \frac{2^{1-\nu}}{\Gamma(\nu)} \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}^\nu K_\nu \del{\sqrt{2\nu} \frac{\norm{x-x'}}{\kappa}}
}
}
\htmlData{class=fragment d-print-none,fragment-index=9}{
\footnotesize
\mathclap{
k_{\infty, \kappa, \sigma^2}(x,x') = \sigma^2 \exp\del{-\frac{\norm{x-x'}^2}{2\kappa^2}}
}
}
$$
$\sigma^2$: variance
$\kappa$: length scale
$\nu$: smoothness
$\nu\to\infty$: Gaussian kernel (RBF)

$\nu = 1/2$

$\nu = 3/2$

$\nu = 5/2$

$\nu = \infty$


$$ k_{\nu, \kappa, \sigma^2}(x,x') = \frac{\sigma^2}{C_\nu} \sum_{n=0}^\infty \del{\frac{2\nu}{\kappa^2} - \lambda_n}^{-\nu-\frac{d}{2}} f_n(x) f_n(x') $$
Examples:



$$ k_{\nu, \kappa, \sigma^2}(i, j) = \frac{\sigma^2}{C_{\nu}} \sum_{n=0}^{\abs{V}-1} \del{\frac{2\nu}{\kappa^2} + \mathbf{\lambda_n}}^{-\nu} \mathbf{f_n}(i)\mathbf{f_n}(j) $$
Examples:



$$ \htmlData{fragment-index=0,class=fragment}{ x_0 } \qquad \htmlData{fragment-index=1,class=fragment}{ x_1 = x_0 + f(x_0)\Delta t } \qquad \htmlData{fragment-index=2,class=fragment}{ x_2 = x_1 + f(x_1)\Delta t } \qquad \htmlData{fragment-index=3,class=fragment}{ .. } $$

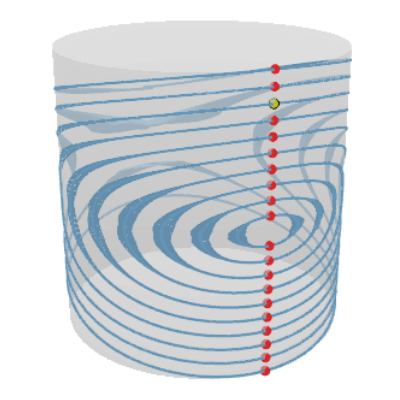


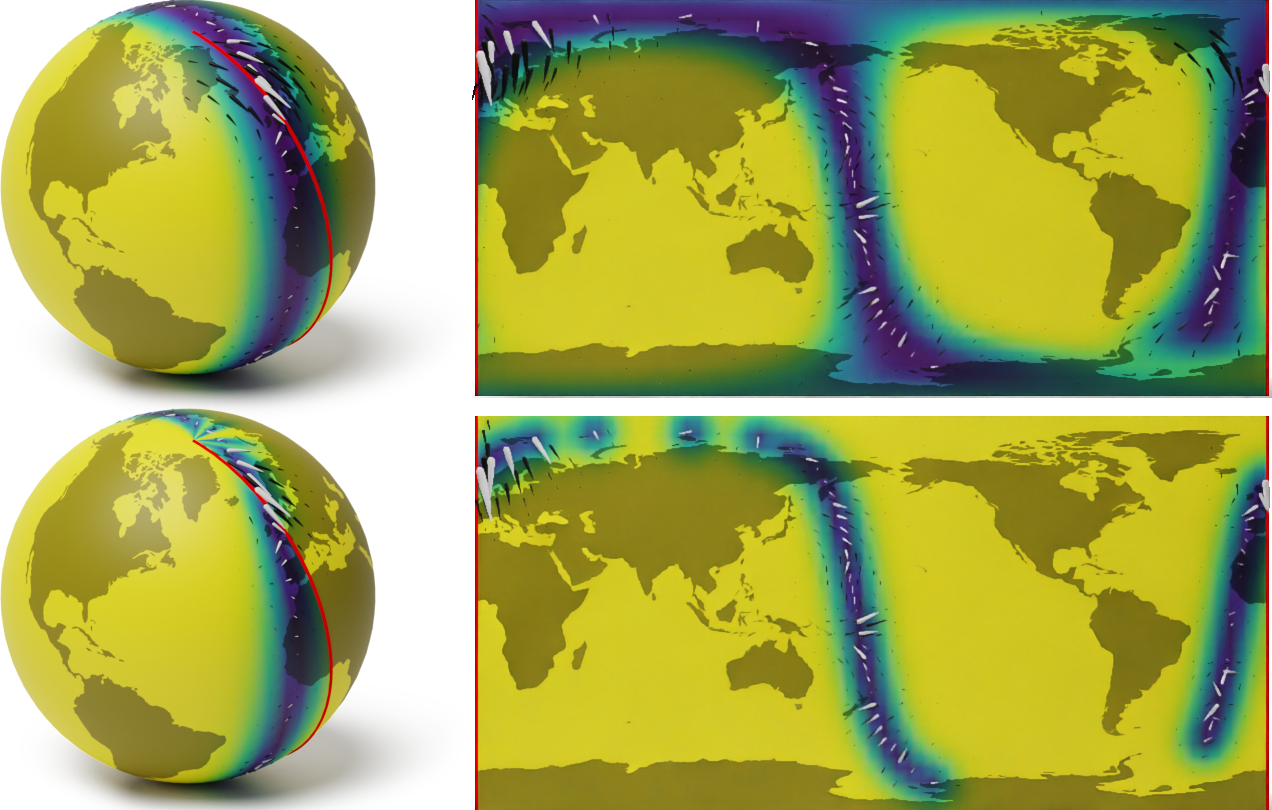
J. Wilson, V. Borovitskiy, A. Terenin, P. Mostowsky, M. P. Deisenroth. Efficiently sampling functions from Gaussian process posteriors. International Conference on Machine Learning, 2020.
V. Borovitskiy, A. Terenin, P. Mostowsky, M. P. Deisenroth. Matérn Gaussian Processes on Riemannian Manifolds.
In Neural Information Processing Systems (NeurIPS) 2020.
V. Borovitskiy, I. Azangulov, A. Terenin, P. Mostowsky, M. P. Deisenroth. Matérn Gaussian Processes on Graphs.
In International Conference on Artificial Intelligence and Statistics (AISTATS) 2021.
J. Wilson, V. Borovitskiy, A. Terenin, P. Mostowsky, M. P. Deisenroth. Pathwise Conditioning of Gaussian Processes. Journal of Machine Learning Research, 2021.
N. Jaquier, V. Borovitskiy, A. Smolensky, A. Terenin, T. Asfour, L. Rozo. Geometry-aware Bayesian Optimization in Robotics using Riemannian Matérn Kernels. To appear in Conference on Robot Learning (CoRL), 2021.
M. Hutchinson, A. Terenin, V. Borovitskiy, S. Takao, Y. W. Teh, M. P. Deisenroth. Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge-Independent Projected Kernels. To appear in NeurIPS 2021.
viacheslav.borovitskiy@gmail.com https://vab.im